Difference between revisions of "Polysemy"
| Line 60: | Line 60: | ||
<math> y_x = e^{-bx}</math>]]] | <math> y_x = e^{-bx}</math>]]] | ||
| − | '''4. Authors:''' U. | + | '''4. Authors:''' U. Strauss, G. Altmann |
'''5. References''' | '''5. References''' | ||
Latest revision as of 12:05, 5 August 2006
1. Problem and history
The simplest problem connected with polysemy is its frequency distribution in the dictionary. One can easily see that in a monolingual dictionary lexical items have different number of explications. Sometimes the explications are numbered and indicate meaning difference or nuance. This is the only source of approaching the problem. The number of meanings of a word is sometimes called semantic size or semantic volume (cf. Tuldava 1998: 119). Some reserchers stated that the mean semantic volume of different word classes differs significantly (cf. Višnjakova 1976; Tuldava 1979; Ufimceva 1968: 89) Historically, G.K. Zipf (1935, 1945a, 1949) was probably the first who has shown that meaning is associated with frequency, with length and other properties analyzed in synergetic linguistics (see Vol. 2). Nevertheless, the distribution of the semantic volume can be studied separately (see Introduction, Chapter 2), since it represents a loop in the system. Another question is the frequency of polysemic words in text. The first trials to find a theoretical distribution can be found in Krylov, Jakubovskaja (1977), Krylov (1982) who derived the geometric distribution, Tuldava (1979) who used on empirical grounds a kind of exponential function and Levickij, Drebet, Kiiko (1999) who used rather the mixed geometric distribution, assuming that the words in the dictionary are of a mixed character. A good survey of problems can be found in Hoffmann (2001).
2. Hypothesis
The number of words (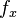 ) with x meanings is a function of x.
) with x meanings is a function of x.
3. Derivation
3.1. Waring distribution
Wimmer and Altmann (1999a) considered the building of polysemy as a simple Poissonian birth-and-death process and set up the equations
(1)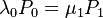
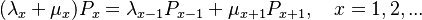
Inserting 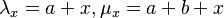 and displacing the distribution one step to the right – because zero-semic words are not taken into account - they obtained the Waring distribution
and displacing the distribution one step to the right – because zero-semic words are not taken into account - they obtained the Waring distribution
(2)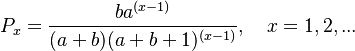
3.2. Bissinger-geometric distribution
Since the Waring distribution can be presented by a backward recurrence formula, Wimmer and Altmann (1999a) consider also the possibility of forward dependence using a parent distribution {Px* }x≥0 and building partial sums in the form
(3)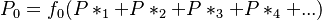
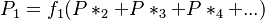
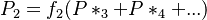
From the great number of possibilities (cf. Wimmer, Altmann 2000) they chose the simple form
(4)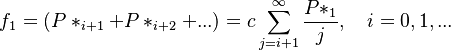
yielding 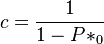 as a normalizing constant.. Using the geometric distribution as parent distribution and displacing the result one step to the right they obtain
as a normalizing constant.. Using the geometric distribution as parent distribution and displacing the result one step to the right they obtain
(5)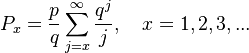
known as Bissinger-geometric distribution (cf. Wimmer, Altmann 1999).
Example: Polysemy in Maori (New Zealand)
Using the data ascertained by V. Krupa, Wimmer and Altmann (1999a) fitted the Waring and the Bissinger-geometric distributions to Maori dictionary data as shown in Table 1.

[[[Please complete:
3.3. Tuldava´s version
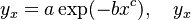 = number of words with x meanings
= number of words with x meanings
3.4. Krylov-Jakubovskaja´s version (
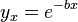 ]]]
]]]
4. Authors: U. Strauss, G. Altmann
5. References
Agricola, E. (1962). Wörter und Wendungen. Wörterbuch zum deutschen Sprachgebrauch. (Hrsg. E. Agricola unter Mitwirkung von H. Görner und R. Küfner). Leipzig: VEB Bibliographisches Institut, 598.
Altmann, G. (1985). Semantische Diversifikation. Folia Linguistica 19, 177-200. Altmann, G., Bagheri, D., Goebl, H., Köhler, R., Prün, C. (2002). Einführung in die quantitative Lexikologie. Götingen: Peust & Gutschmidt.
Altmann, G.,Beöthy, E., Best, K.-H.(1982), Die Bedeutungskomplexität der Wörter und das Menzerathsche Gesetz. Zeitschrift für Phonetik, Sprachwissenschaft und Kommunikationsforschung 35 (5), 537-543.
Altmann, G., Best, K.-H., Kind, B. (1987). Eine Verallgemeinerung des Gesetzes der semantischen Diversifikation. Glottometrika 8, 130-139.
Andreevskaja, A.V. (1990). Kvantitativnoe issle-dovanie polisemii kornevych slov russkogo jazyka XI-XX vekov. Ucenye Zapiski Tartuskogo Universiteta 912, 3-11.
Andrukovic, P.F., Korol’ov, E.I. (1977). O statisticeskich i leksikogrammaticeskich svojstvach slov. Naucno-technic¡eskaja informacija, ser. 2 (2), 1-9.
Arapov, M.V. (1987). Upotrebitel’nost’ i mnogoznacnost’ slova. In: Ucenye Zapiski Tartuskogo Universiteta 774. Tartu, 15-28.
Drebet, V.V. (1996). Stilistische Kennzeichen der polysemen Substantive in der deutschen Gegenwartssprache. Naukovy Visnyk Cerniveckoho Universytetu 2, 55-60.
Drebet, V.V., Levickij, V.V., Cherubim, D. (1996). Morphologische Faktoren bei der Polysemie der deutschen Adjektive. Naukovy Visnyk Cerniveckoho Universytetu 1, 29-32.
'Fickermann, I., Markner-Jäger, B., Rothe, U.(1984). Wortlänge und Bedeutungskomplexität. Glottometrika 6, 115-126. Bochum: Brockmeyer.
Gindin, S.I. (1982). Castota slova i jego znacimost’ v sisteme jazyka. In: Lingvostatistika i vycislitelnaja lingvistika 8. Tartu, 22-53.
Guiraud, P. (1954). Les caractèrs statistique du vocabulaire. Paris: Press universitaires.
Hammerl, R. (1991). Untersuchungen zur Struktur der Lexik: Aufbau eines lexikalischen Basismodells. Trier, WVT.
Hoffmann, Ch. (2001). Polylexie lexikalischer Einheiten in Texten. In: Uhlířova, L., Wimmer, G., Altmann, G., Köhler, R. (Eds.), Text as a linguistic paradigm: levels, constituents, constructs. Festschrift in honour of Ludek Hřebíček: 76-97. Trier: WVT.
'Kapatruk, M.D. (1980). Metody vyvcennja osnovnoho znacennja slova. Movoznavstvo 5, 75-77.
Kijko, S.V., Kijko, J.J. (1996a). Kvantytatyvne dos-lidžennja polisemii dijesliv sucasnoji nimec’koji movy. Naukovy Visnyk Cerniveckoho Universytetu 1, 32-38.
Kijko, J.J., Kijko, S.V. (1996b). Polysemie der Verben und ihre stilistische Markierung. Naukovy Visnyk Cerniveckoho Universytetu 2, 60-64.
Köhler, R. (1986). Zur linguistischen Synergetik. Struktur und Dynamik der Lexik. Bochum: Brockmeyer.
Krott, A. (2002). Ein funktionalanalytisches Modell der Wortbildung. In: Köhler, R. (ed.), Korpuslinguistische Untersuchungen in die quantitative und systemtheoretische Linguistik: 75-126. http://ubt.opus.hbz-nrw.de/volltexte/2004/279/
Krylov, Ju.K. (1982a). Ob odnoj paradigme lingvostatističeskich raspredelenij. Acta et Commentationens Universitatis Tartuensis 628, 80-102.
Krylov, Ju.K. (1982b). Eine Untersuchung statistischer Gesetzmäßigkeiten auf der paradigmatischen Ebene der Lexik natürlicher Sprachen. In: Guiter, H., Arapov, M.V. (eds.), Studies on Zipf´s law: 234-262. Bochum: Brockmeyer.
Krylov, Ju.K., Jakubovskaja, M.D. (1977), Statisticeskij analiz polisemii kak jazykovoj universalii i problema semanticeskogo toždestva slova. Naucno-techniceskaja informacija, ser. 2,(3), 1-6.'
Kucera, H., Francis, W. N. (eds.)(1967). Computational analysis of present-day American English. Providence, N.J.: Brown University Press.
Lehrer, A. (1974). Homonymy and polysemy: measuring similarity of meaning. Language Sciences 32, 33-39.
Levickij, V. V. (1985). Opyt eksperimental’nogo razgranicenija leksiceskoj polisemii i omonimii. In: Psicholingvisticeskie issledovanija. Leksika. Fonetika: 4-14. Kalinin: Kalininskij Universitet.
Levickij, V. (2005). Polysemie. In: Köhler, R., Altmann, G., Piotrowski, R.G. (eds.), Handbook of Quantitative Linguistics: 458-464. Berlin: de gruyter.
Levickij, V.V., Drebet, V.V., Kijko, S.V. (1999). Some quantitative characteristics of polysemy of verbs, nouns and adjectives in the German language. J. of Quantitative Linguistics 6, 172-187.
Levickij, V.V., Drebet, V.V., Kijko S.V. (1999). Some Quantitative Characteristics of Polysemy of Verbs, Nouns and Adjectives in the German Language. Journal of Quantitative Linguistics 6(2), 192-197.
Levickij, V.V., Kijko, J.J., Spolnicka, S.V. (1996). Quantitative analysis of verb polysemy in modern German. Journal of Quantitative Linguistics 3 (2), 132-135.
Malov, A. V. (1988). Rangovye polisemicskie ras-predelenija leksiki tolkovych slovarej russkogo i anglijskogo jazykov. Ucenye Zapiski Tartuskogo Universiteta 827, 111-115.
Moskovic, V.A. (1969). Statistika i semantika. Moskva: Nauka.
Muravycka, M.P.' (1975). Psycholinhvistycnyj analiz leksycnoji omonimiji. Movoznavstvo 3, 59-67.
Obuchova, N.V. (1986). O specifike raspredelenija mnogoznacnosti leksiceskich jedinic v kitajskom jazyke. Ucenye Zapiski Tartuskogo Universiteta 745, 119-128.
Olšanskij, J.G., Skiba, V.P. (1987). Leksiceskaja polisemija v sisteme jazyka i tekste. Kišynjov: Štiinca.
Papp, F.O. (1967)., O nekotorych kolicestvennych charakteristikach slovarnogo sostava jazyka. Slavia, vii, 51-58.
Polikarpov, A.A. (1987). Polisemija. Sistemno-kvantitativnye aspekty. In: Tuldava, J.A. (ed.), Kvantitativnaja lingvistika i avtomatičeskij analiz tekstov: 135-154. Tartu: Učenye zapiski Tartuskogo gosudarstvennogo universiteta 774.
Polikarpov, A. A. (1990). Leksi¼ñêôœ`eskaja polisemija v evolucionnom aspekte. Ucenye Zapiski Tartuskogo Universiteta 974, 77-86. Tartu.
Polikarpov, A.A., Krjukova, O.S. (1989). O sistemnom sootnošenii kratkogo i srednego tolkovych slovarej russkogo jazyka. Ucenye Zapiski Tartuskogo Universiteta 872, 111-125.
Polikarpov, A.A., Kurlov, V.J. (1994). Stilistika, semantika, grammatika: opyt analiza sistemnych vzaimosvjazej (po dannym tolkovogo slovarja). Voprosy jazykoznanija 1, 62-82.
Rothe, U. (1983). Wortlänge und Bedeutungsmenge. Eine Untersuchung zum Menzerathschen Gesetz an drei romanischen Sprachen. Glottometrika 5, 101-112.
Sambor, J. (1984). Menzerath’s law and the polysemy of words. Glottometrika 6, 94-114. Bochum: Brockmeyer.
Schierholz, S.J. (1991). Lexikologische Analysen zur Abstraktheit, Häufigkeit und Polysemie deutscher Substantive. Tübingen: Niemeyer.
Tuldava, J. (1979). O nekotorych kvantitativno- sistemnych charakteristikach polisemii. Ucenye Zapiski Tartuskogo Universiteta 502, 107-141.
Tuldava, J. (1987). Problemy i metody kvanti-tativno-sistemnogo issledovanija leksiki. Tallinn: Valgus.
Tuldava, J. (1998). Probleme und Methoden der quantitativ-systemischen Lexikologie. Trier: WVT.
Višnjakova, S.M. (1976). Opyt statisti¼ñêôœ`eskogo issledovanija mnogozna¼ñêôœ`nosti slov anglijskogo jazyka. Vycislitel’naja lingvistika. 168-178.
Wimmer, G., Altmann, G. (1999a). Rozdelenie polysémie v maorijčine. In: Ondrejovič, S., Genzor, J. (eds.), Pange lingua. Zborník na počest´ Viktora Krupu: 17-24. Bratislava: Veda.
Wimmer, G., Altmann, G. (2000). On the generalization of the STER distribution applied to generalized hypergeometric parents. Acta Universitatis Palackiensis Olomouciensis, Facultats rerum naturalium Mathematica 39, 215-247.
Wolff, D. (1972). Bedeutungshäufigkeit und ihr statistisches Verhalten. Beiträge zur Linguistik und Informationsverarbeitung 22, 33-44.
Zipf, G.K. (1935).The psycho-biology of language. Boston: Houghton Mifflin.
Zipf, G.K. (1945a). The meaning-frequency relationship of words. J. of General Psychology 33, 251-255.
Zipf, G.K. (1949). Human behavior and the principle of least effort. Cambridge: Addison-Wesley.